Diffusion models导读
背景
很多从深度学习开始接触算法的同学,一开始对Diffusion model的论文会有点不适应。和我们常见的深度学习论文不同,Diffusion model用了不少数学工具,而这几年数学工具用的比较多的深度学习工作的出圈度都不高。
如果你对数学公式不反感,个人建议从****Understanding Diffusion Models: A Unified Perspective** 开始读。这篇相对于其他资料,作者对读者的背景要求最少,全篇读下来很少需要再找额外资料辅助。然后可以读**What are Diffusion Models?** 和 Generative Modeling by Estimating Gradients of the Data Distribution,这两篇文章写的很好,大部分学习资料也都在引用它们,相对于前面一篇,写的比较简洁,对读者背景要求高一些。接着可以找点代码实现看下,推荐下huggingface的The Annotated Diffusion Model,**基于Pytorch的demo实现,感受一波细节。最后,必须推荐知乎上的讨论:**diffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN?****其中特别推荐我想唱high c的答案,但不建议一开始毫无了解的时候去研究这些回答,对读者背景知识假设有点多。当然,如果相对于数学公式,你更熟悉代码,也可以先从huggingface的那篇开始,它的基本介绍写的即简洁又易懂。
本文不是捷径,只是个搬运工,希望能减少一些同学在学习过程中的产生的不适感,帮助更多的同学了解Diffusion model。
基本概念
我们先看下Generative Model核心要干什么,引用下Song在blog里面的一段话:
Suppose we are given a dataset ${x_1,x_2,…,x_N}$, where each point is drawn independently from an underlying data distribution $p(x)$. Given this dataset, the goal of generative modeling is to fit a model to the data distribution such that we can synthesize new data points at will by sampling from the distribution.
更通俗一点的描述,我们看到的现实世界中的各种图片,都可以理解成已经观察到的数据,也就是上文中的dataset,理论上必然存在一个分布$p(x)$可以描述它们,如果我们能够建立一个模型,找到合适的参数去学习到这个分布的具体形式,我们就能够再从这个分布中采样出我们想要的数据,也就是生成式(Generative)模型核心的想法。
但现实世界中这个分布$p(x)$一般很复杂,我们很难真的完全建模出来。学术界在生成式模型耕耘多年,在我个人学习的体验出发,从VAE出发切入去理解Diffusion最容易。在讨论VAE之前,我们先借鉴下****Understanding Diffusion Models: A Unified Perspective中提到的一个**寓言故事。
Allegory of the cave

这个寓言故事大致在描述,把一群人如图所示的关起来,永远只能看岩壁上的二维画面,这个二维画面的影像是外部三维世界的物体经过一个固定的火把后在岩壁上的投影。岩壁上二维的画面显然是由外部三维实体决定的。进一步拓展思路,很有可能我们在现实世界中观察到的很多现象(数据)是从更高维度投影过来。
换一句话说,这个寓言故事表达了,我们观察到的数据分布有可能是被另一个分布所决定。更加严谨的描述:存在隐变量z,决定了我们观测到的数据x的分布,如图所示:
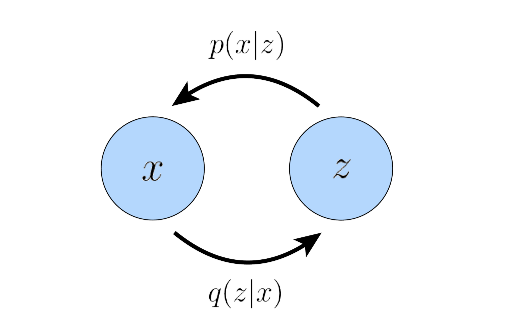
考虑到高维分布过于复杂,一般情况,$z$的维度会比$x$小。
VAE的基本思路
在VAE的架构中,设计两个网络,一个网络做Encoder,将观察的数据$x$映射到隐变量$z$上,另一个网络做Decoder,从采样的$z$中解码回$x$。从实践的角度,VAE需要训练两套参数$\theta$和$\phi$,即$p_\theta(x|z)$和$q_\phi(z|x)$分别对应encoder和decoder,对应上图的中的真实分布$q$和$p$。本文不准备讲非常详细的数学公式推导,网上已经有足够多的资料,而且知乎输入公式很累。只针对关键点做提醒,再补充一些背景知识。
VAE的目标函数采用的是最大似然(likelihood-based)的路线,即对观察到的数据$x$计算最大$p(x)$,借助数学工具ELBO(Evidence Lower Bound),可以得到最大似然分布的一个下界。
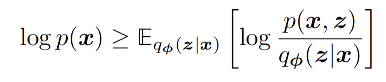
再经过简单的变换,可以得到目标函数的具体实现方式。
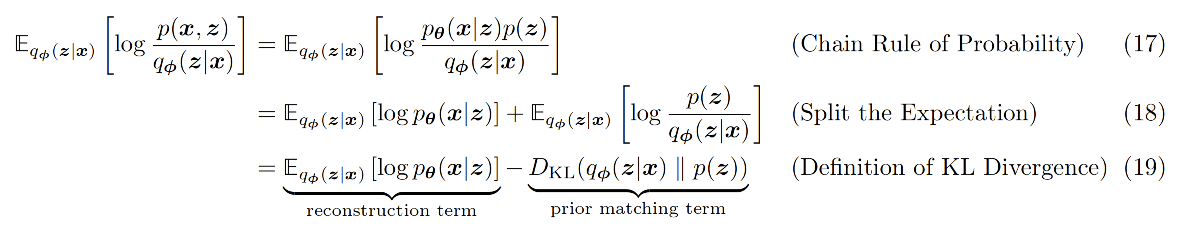
这个目标函数的两项都有很直观的解释,第一项代表Decoder的时候尽量接近原图,第二项代表Encoder的分布要接近真实分布$p(z)$。
讲到这里好像VAE很完美,问题都解决了,但我们知道在生成领域,前几年效果比较好的都是GAN,VAE并不出彩。问题在于这个ELBO,它只是个下界,离真实分布很远的下界也是下界。必须把这个下界抬的足够高才能得到一个好的效果,因此它的$q_\phi$和$p(z)$的分布选择很关键。但由于需要用深度学习网络来建模近似分布$q_\phi$,而深度学习的优化算法是基于后向传播算法(Back Propagation),但VAE需要从分布$q_\phi$中去采样出x,采样这个操作会打断梯度传递。
幸运的是,如果我们选择近似分布的时候基于高斯家族分布,可以用参数重整化(reparameterization trick)的技巧来绕过该问题,即从一个高斯分布$x \sim N(x;\mu, \sigma^2)$中采样,可以被写成下面的公式,即可以求梯度了。
$$ x= \mu + \sigma * \epsilon $$
另外,在计算两个分布是否接近,我们常用KL divergence,如果是高斯分布的比较,它直接有解析解。我们上学学概率论的时候,发现大家都很喜欢用高斯分布去建模,它不合理但架不住高斯分布实在有太多好用的特性。但反过来,又限制了VAE的分布选择。当然有很多工作在尝试解决这个问题。
小总结下,VAE算法在实现的时候增加了多个假设,有些牵强,反过来限制了它能力的上限。
Diffusion Model的基本概念
业界针对VAE的问题做了很多尝试,DM可以算作是其中一种比较成功的尝试。以图片生成举例,VAE想一步到位,同时训练Encoder和Decoder,能够将原始图片映射到隐变量中,又能解码回来,想想都很难。有没有什么办法可以降低问题的难度?一个常见的思路是将困难的问题分而治之,即能不能只训练Encoder或Decoder?能不能把问题分解成一个个子问题?
DM它很大胆的直接去掉了encoder部分的学习。我们知道,如果给一张图片一步步不停的加高斯噪音,经过足够多步,这张图一定会变成纯高斯噪音,类似下图的效果。

可以理解成,对比VAE,DM的Encoder过程是固定的,事先写好,不需要建模和学习。DM只关心如何学好Decoder,即逆向过程中如何重建数据。
由于Encoder过程是一步步做的,反之DM的Decoder也可以是一步步做,即Decoder不需要一下子就将整张图片生成出来,而是一步步的去恢复图片,逆向整个Encoder的过程,大大降低了问题的难度。
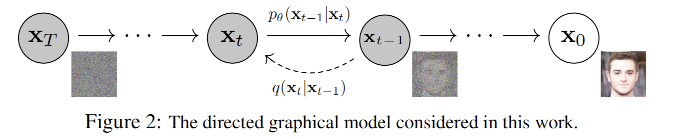
如上图所示,由于Encoder的时候用的高斯噪音分布,即每个$q(x_t|x_{t-1})$都是高斯分布,如果每步足够小,那么Decoder时候每一步的分布即$q(x_{t-1}|x_t)$也是高斯。那么原先VAE使用的reparameterization trick、KL divergence等技巧用起来就合理,理论上ELBO的下界能比VAE学的更好。
结合深度学习角度去理解
简单总结下,DM的基本流程是:
- 先做前向处理(Forward diffusion process),输入一张原始图片,经过T步迭代,将原始图片转换为纯高斯分布的噪音图,其中每一步给原图加的噪音都是事先定好的。定一个这个分布为q。
- 逆向这个过程(Reverse diffusion process),训练一个神经网络来学习分布$p_\theta$来逐步的将噪音图恢复到原图。
经过一系列的推导,DM的ELBO如下:
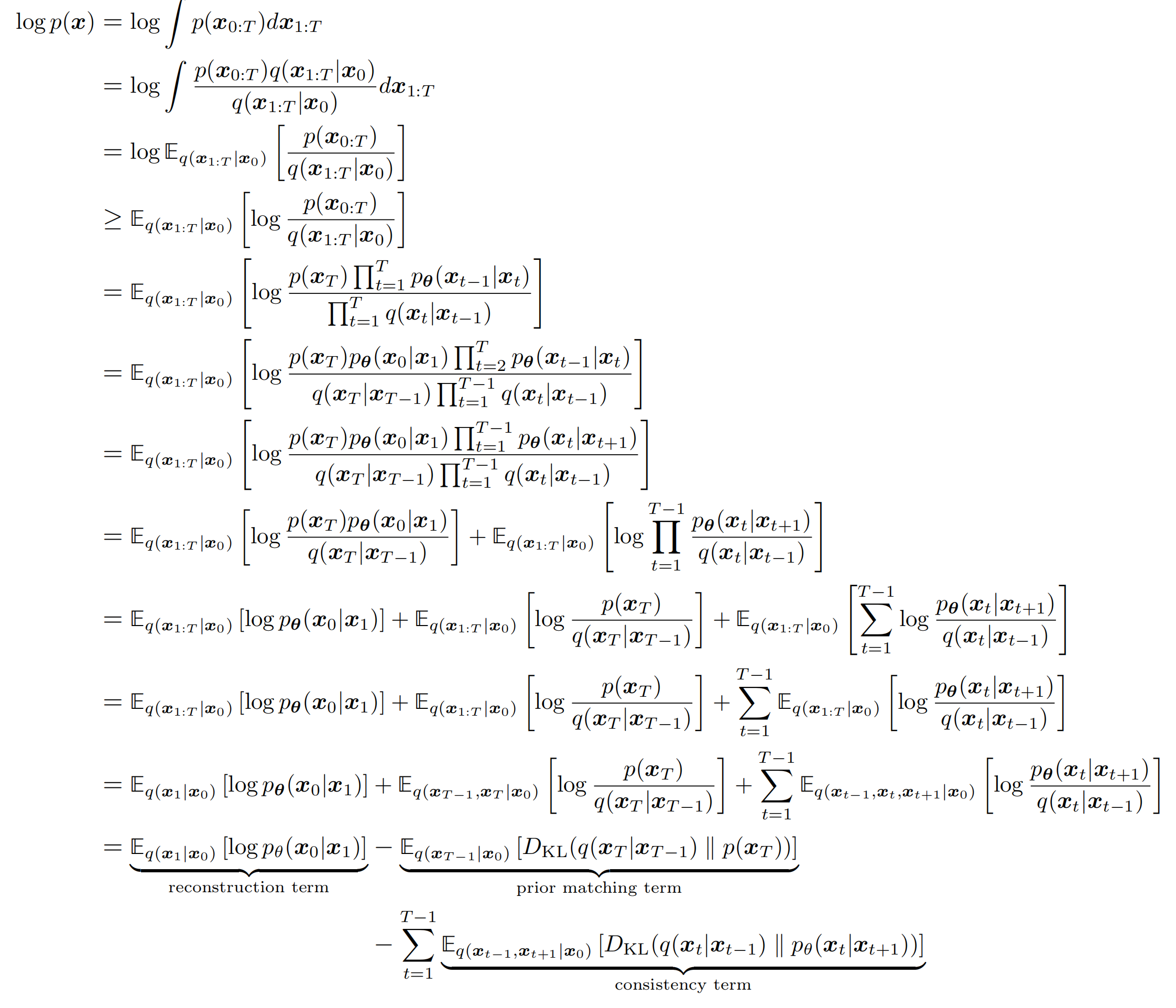
上述的目标函数还太麻烦,再经过一些列的推导和简化,最终的object function长这样:
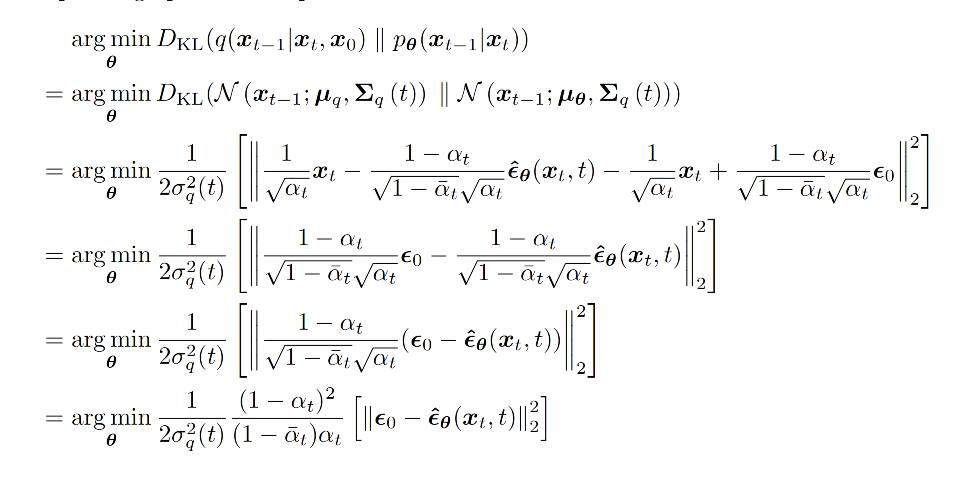
即每一步最小化模型预测的噪音分布和高斯噪音之间的距离。这部分在下文看代码的时候可以更直观的理解。
再次强调,需要注意在前项处理(forward process)的时候,没有参数要学习,每一步都是增加事先设计好的高斯分布的噪音。这和VAE很不一样,可以理解成encoder部分是不需要用网络去学习和训练。
DM的目标函数咋一看挺麻烦的,但是经过应用一系列的数学工具后,模型的loss变的非常简洁,且不需要直接去建模输入图片的真实分布,而是去建模每次增加的噪音分布。如下图中的公式,其中$\epsilon_\theta$是模型要学习的部分。
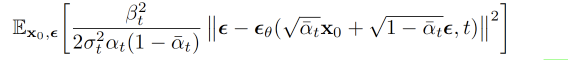
网络结构目前主流都选择Unet,据说Unet结构对DM很重要,但这部分还没有深究,不展开。DM在代码层面的实现相对简单,代码量不大,大家可以多找几个实现看看。本文主要参考huggingface的分享,结合DDPM论文中train和sample(即predict)的伪代码,简单梳理下:
训练过程

- 输入$x_0$,即训练数据集中的原始图片
- t这一步可以先不深究,必须依靠更多的数学工具才能理解。这里简单来讲,应用了数学工具后,发现不需要按forward过程中描述的,一步步的从0加到t。因此for循环加sample一部分t在train的时候是更有效率的。
- $\epsilon$:从高斯分布中采样的噪音;
- 将$x_0$,$\epsilon$,$t$输入到我们的深度学习模型中,计算loss的梯度,其中$\bar{\alpha}$是预设好的参数;模型输入是$x_0$,$\epsilon$,$t$,loss是计算模型预测的噪音分布和高斯噪音的差值(huber、l2都可以)
稍微解释下t的采样问题,在forward过程中,从$x_0$加noise到$x_T$,其每一步的增加的高斯噪音如下,其中$\beta$是事先定好的策略:
$$ q(x_t|x_{t-1}) = N(x_t;\sqrt{1-\beta} x_{t-1}, \beta_t I) $$
这个公式算起来还有点麻烦,每次要先把t-1算出来,我们可以用gaussian的reparameterization的技巧,让$x_t$的计算更简单;
$$ x_t = \sqrt{\bar{a}_t}x_0 + \sqrt{1-\bar{a}_t}\epsilon $$
这里$\epsilon$是高斯参数化技巧的一部分,这里可以重写$q(x_t|x_0)$,即每次计算$x_t$只和$x_0$相关,而Diffusion的loss是一个累加的L,则训练时就可以采样任意的t去计算,效率更高。
$$ q(x_t | x_0) = N(x_t; \sqrt{\bar{a}_t}x_0, (1-\bar{a}_t)I) $$
预测过程(从概率的角度即Sample过程)

预测部分就很简单,从高斯噪音图开始,从T时刻到T0,依靠$x_t$、模型输出的$\epsilon_\theta$和高斯噪音恢复每一步的$x_{t-1}$。一步步的去噪。
总结
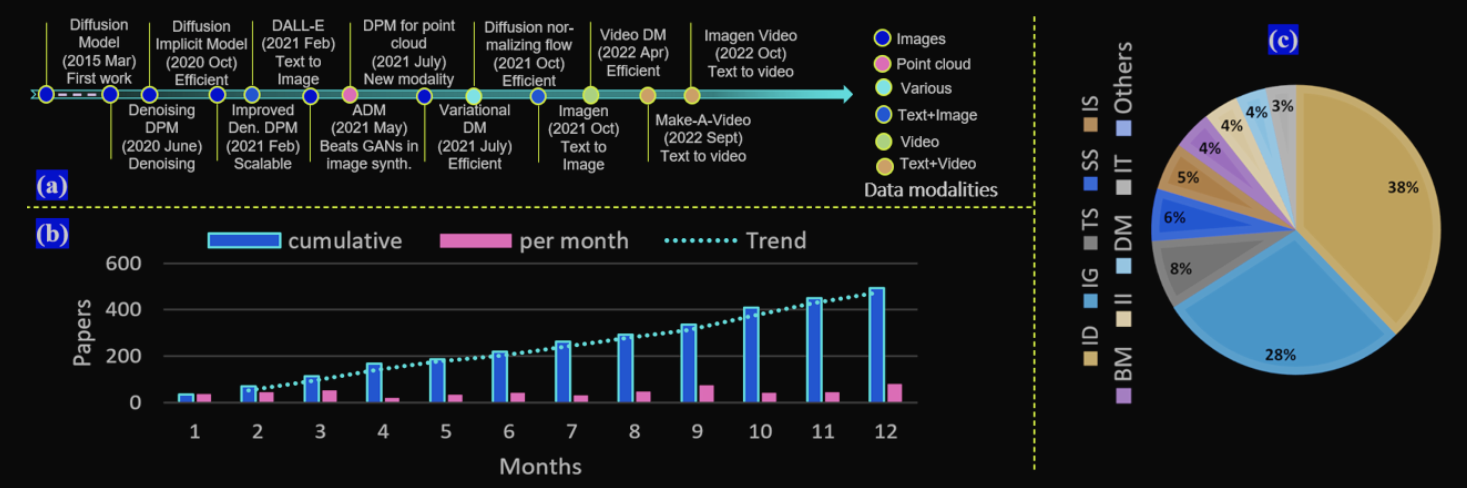
写到这里文章已经很长,但只梳理了最基本的DM概念,一些最新的发展和DM本身的问题都没有涉及,从下图中可以看出DM领域近期非常火热,网上有大量的相关工作,感兴趣的同学可以慢慢去探索。
本文从导读的角度梳理下近期学习Diffusion model的一些心得,希望能帮大家建立一些基本概念,减轻学习时候的不适感。再次推荐下这篇文档,感受下它的目录结构,非常详细且循序渐进。

参考资料
**Understanding Diffusion Models: A Unified Perspective
Generative Modeling by Estimating Gradients of the Data Distribution
diffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN?
https://arxiv.org/pdf/2006.11239.pdf
https://arxiv.org/pdf/1503.03585.pdf
https://arxiv.org/pdf/2209.02646.pdf
https://arxiv.org/pdf/2210.09292.pdf
https://arxiv.org/pdf/2209.00796v9.pdf
https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
https://www.youtube.com/watch?v=HoKDTa5jHvg
https://www.youtube.com/watch?v=fbLgFrlTnGU